Web Scraping with Proxies: The Complete Guide to Scaling Your Web Scraper
Proxies are a pretty important part of any serious web scraping project. Adding proxies to your scraping software offers a number of benefits, but it can be hard to know how to get started.
How do you integrate a proxy into your scraping software? How many proxies do you need for you project? What type of proxies do you need and where should you get them from?
In this article, I’ll explain everything you need to know about adding proxies to your web scraping software. Let’s dive in.
What is a Proxy Server?
While there are many different types of proxies and different protocols you may use to connect to them, the essence of a proxy is that it’s an extra server between you and the site you’re trying to visit.
When you make an HTTP request to a site using a proxy server, instead of travelling directly to that site, your request first passes through the proxy server, and then on to your target site.
Thus, the proxy server is making the request on your behalf (“by proxy”) and then passing the response from the target site back to you.
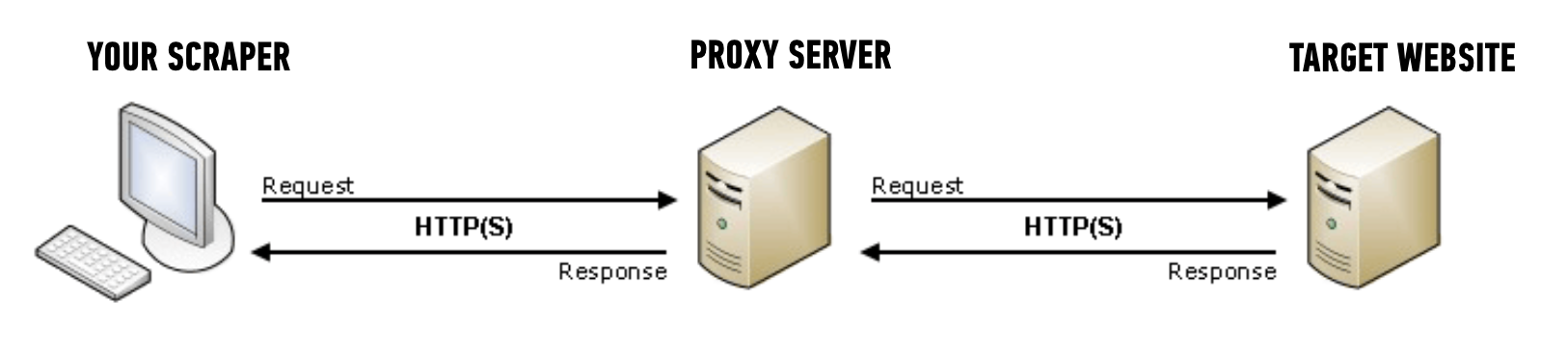
Importantly, from the perspective of the target site, they have no idea that the request is being proxied. They simply see a normal web request coming in from the proxy server’s IP address.
With most good proxy software, there is no information about the original machine that sent the request. There is nothing special or unique about a request that arrives at the target site through a proxy versus one that does not.
Why Use Proxies for Web Scraping?
There are two main benefits to using proxies for your web scraping project:
- Hiding your source machine’s IP address
- Getting past rate limits on the target site
The main benefit of proxies for web scraping is that you can hide your web scraping machine’s IP address. Since the target site you’re sending requests to sees the request coming in from the proxy machine’s IP address, it has no idea what your original scraping machine’s IP is.

Outside of web scraping, proxy servers are often used to get around geo-IP based content restrictions. If someone wants to watch an Australian TV program but they don’t have access from their home country, they can make the request for the show through a proxy server that’s located in Australia (and has an Australian IP address) to get past the restriction, since their traffic seems to be coming from the Australian IP address.
Besides masking your original IP address, another big benefit of using proxies with web scraping is getting past rate limits on your target site.
Many large sites have software in place to detect when there are a suspicious number of requests coming in from one IP address, since this usually indicates some sort of automated access – it could be scraping, or something security related like fuzzing.
The way this rate limiting software is usually setup, if too many requests come in from one IP address in a short amount of time, then the site will return some sort of error message to “block” future requests from that client for a pre-set period of time.
If you’re hoping to ingest more than a few thousand pages of content from a large target website, then you’ll likely run into rate limits at some point.
In order to get around this type of restriction, you can spread a large number of requests out evenly across a large number of proxy servers. Then the target site will only see a handful of requests coming from each individual proxy server’s IP address, meaning they’ll all stay under the rate limit while your scraping program is still able to ingest the data from many requests at once.
How Many Proxy Servers Do You Need?
Since most people who are ingesting more than a few thousand pages from the target site end up needing to use proxy servers, I have this conversation with clients a lot.
Ultimately, without seeing the code that your target site is using to implement the rate limit, we can only really guess at how to stay below their rate limit thresholds, but there are some sane ranges I use for back of the napkin math.
You figure the target site doesn’t want to throttle legitimate human users who are power users on the site. Depending on the site’s content, a human user may make between 5-10 legitimate requests per minute, over a sustained period.
A human user may open a bunch of links in new tabs, making lots of requests within just a few seconds, but then there will be a pause as they view the content on those pages before they make more requests.
This translates to roughly 300-600 requests per hour, as an upper bound of what a legitimate human user would be making, before things start to look suspicious. I usually use 500 request per hour from one IP address as my rule of thumb for avoiding rate limits.
Again, there is no hard math here, since we’re guessing about how the target site may have implemented their rate limit. Some sites may be more aggressive and have even lower limits before they’ll start to throttle requests from an IP address.
In order to figure out the number of proxy servers you need then, you can divide the total throughput of your web scraper (number of requests per hour) by the threshold of 500 requests per IP per hour to approximate the number of different IP addresses you’ll need.
If you can ingest 100,000 URLs per hour, then you’ll need: 100,000 / 500 = 200 different proxy IP addresses to be right at the (approximate) rate limit.
That means, if you perfectly rotate each of the 100,000 request per hour over the 200 IP addresses, you’ll be just at the 500 requests per hour limit from one IP address.
If you can afford to, it’ll make your life a lot easier if you add a safety multiple of 2-3x to that number so that you’re not constantly bumping into rate limits. So for the 100,000 requests per hour, I’d recommend using about 400-600 proxy server IP addresses.
What Type of Proxy Server Do You Need?
Even if you’re a expert server admin, it’s really not worth trying to setup your own proxy servers. The main goal is to be able to fan your requests out through a large number of IP address.

Manually administering hundreds of proxy servers is untenable, and even using automated software to manage your own pool of machines likely isn’t worth the hassle.
You’ll want to change the pool of IP addresses you use from time to time, as good “scraping hygeine”, which would require setting up new pools of servers periodically.
Proxy software is such a commodity now, it’s much better to rent a slice of someone else’s proxy infrastructure than build your own.
In terms of deciding which proxy servers to use, there are really two main factors to consider:
- Whether you want exclusive access to the server (Dedicated versus Shared)
- What protocol you’d like to connect to the proxy over (SOCKS versus HTTP)
In general, you pay a premium for getting dedicated proxy servers. The main benefit for web scraping is that you know that no one else is going to be messing with your rate limit calculations by also making requests to your target website through the same IP address.
In general, I recommend clients to use the cheaper shared proxies, since you can get a lot more of them for the same price as a dedicated server. The risk of someone else also scraping the same site at the same time through the same proxy IP seems exceedingly low.
The other thing to consider is how you’ll connect to the proxy server from your web scraping program. The two main protocols for connecting are SOCKS and HTTP, but most proxy providers offer both connection types, so this won’t really be much of a differentiating factor.
Recommended Proxy Service Providers
There are three providers I usually turn to with scraping projects for my clients:
- Proxy Bonanza has some of the best prices I’ve found on shared proxy servers. While most providers charge by the month, Proxy Bonanza allows you to rent proxy server access for a week, which is a great way to save money for a one-time scrape.
- Squid Proxies provides scraping infrastructure for long-term, large-scale scrapes. They have good support and their proxy servers are blazing fast.
- Smartproxy offers a residential proxy service which is great if you really need to get past some determined anti-scraping measures. Their proxy IP addresses aren’t in data centers, so your traffic will blend in well with normal end users.
I’ve used all of them for projects in the past, and they are great choices for renting access to web scraping proxy servers.
Integrating Proxies into Your Scraping Software
Adding in a list of proxies to your existing scraping software should be relatively straightforward. There are really only two parts to any proxy integration:
- Passing your web scraper’s requests through the proxy
- Rotating proxy server IP addresses properly between requests
Step #1 is usually very simple, but will depend on the library you’re using in your web scraping program. In the python requests library, it is as simple as:
import requests
proxies = {'http': 'http://user:pass@10.10.1.10:3128/'}
requests.get('http://example.org', proxies=proxies)
Note that you’ll likely need to concatenate a few pieces of information together in your proxy connection URL – like the protocol, username, password, ip address and port number. The proxy provider should give you the values you’ll need to properly connect to the servers you’ve rented.
Once you’ve got your proxy connection URL built, you’ll need to consult your network request library’s documentation to see how you’re supposed to pass the proxy information through, so that each request is properly routed through a proxy.
If you’re not sure whether you’ve done the integration correctly, it’s worth sending some test requests through to a site like ipinfo.io and then inspecting the response you’re getting back. That site returns information about the IP address it sees the request coming from, so if everything is setup correctly, you should be seeing the proxy server’s information in the response, not your own machine.
Step #2 can get a bit more complicated, depending on how much parallel processing you’re doing and how slim of a margin you want to keep with the target site’s rate limit.
If you’re only using one worker/process/thread to make sequential requests one after the other, then you can keep a simple list of proxies in memory and pop a proxy off the end of the list for each request, inserting it back at the other end after it’s been used.
In addition to having simple code, this also ensures even rotation across all of the IP addresses you have access to, and is better than “randomly” picking a proxy from the list for each request, where you may end up choosing the same proxy several times in a row.
If you’re running your web scraper in a setup where there are many workers making requests to the target site in parallel, then you’ll need to have some global proxy IP tracking to make sure the same IP isn’t being used by multiple workers repeatedly in a short window, lest you risk that IP getting rate limited by the target site and “burned” – where it’s no longer good for passing requests through.
You’ll also probably want to have a mechanism for detecting when a proxy IP has been burned – the target site returns some sort of error response indicating you’ve been rate limited. If that happens, then you can put the proxy in “time out,” usually for a few hours, until the target site is no longer rate limiting requests from that IP address, and you can start using it again. It’s good to have some monitoring and metrics for how often this is happening.
Ultimately, how complex your proxy rotation logic needs to be comes down to how tight you want to cut it when you do your proxy math above. If you can spend a bit more when buying proxies, you can save yourself hours of development time trying to rotate and monitor your proxies to get things “just right.”
It’s up to you and your team to figure out the right balance there.
If you have a big web scraping project you need help with, I’d love to chat!
